miniレクチャー
たくさんの意見、その傾向をつかむ ~文章を分析するテキストマイニング~
たくさんの意見からその傾向を知る
アンケートで「この商品についての感想をお聞かせください」と、自由に感想を聞くことがあります。これまでですと、こういった自由記述文の集計は、1つ1つの文章を読んでは主観で分類するので、時間がかかり、客観性にも疑問が残ることがあり、できれば選択肢の設問にする方が好まれてきました。
これに対して、大量の自由記述文(テキスト型データ)からコンピュータを用いて自動的に言葉を取り出し、さまざな統計手法を利用して有益な情報を取り出す「テキストマイニング」という手法があります。
これは、1つ1つの文章を単語(基本要素)に分かち、その数を数えたり、単語と単語のつながりを調べ、複数の文章に同じ単語の組み合わせがどれぐらいあるかを集計したりして、全体的な傾向を明らかにしようというものです。こうすることで、どういった感想が多かったか、どんな点に着目していたかを明らかにしたり、希少意見も拾うことができます。レビューサイトや口コミサイトの書き込みの分析をしたり、文学作品をまるごとテキストマイングすると、作者の癖をつかむことができるので、ゴーストライターや贋作を発見するといった使い方もできます。
テキストマイニングで傾向をみてみよう
では、実際の分析をみてみましょう。
経営学科では、前身の社会情報学科の頃から、「ニュース時事能力検定」の模擬問題を提供してきました。すでに連載は修了しています。全ての問は、学科の「めざせニュース検定」のサイトで見ることができます。
ニュース検定は次のような4択の出題になっている。

この質問文をテキストマイニングにかけて、出題傾向をさぐってみましょう。分析は、マネジメント研究科修士2年次の稲田愛さんに行ってもらいました(キャンパスライフに彼女のコラムがあります)。
問題全621問のうち、学生が作成した9問を除く612問を分析対象とします。抽出する品詞や語の取捨選択を行った後、テキストマイニング専用ソフトウェアである樋口耕一氏のKH Coderを使います。
図1は、共起ネットワーク図といって、単語Aと単語Bが1つの文書に同時に出てくる(共起する)ことが多い場合、その単語どうしをつなげ、その頻度の多さを円の大きさやつながりの線の太さなどで表現しています。頻度の少ないものは現れません。つまり、ここにある「島」のようなものは、つながりの強い(同時に出現した回数が多い)ブロックであり、全体的にその話題が多かったということになります。
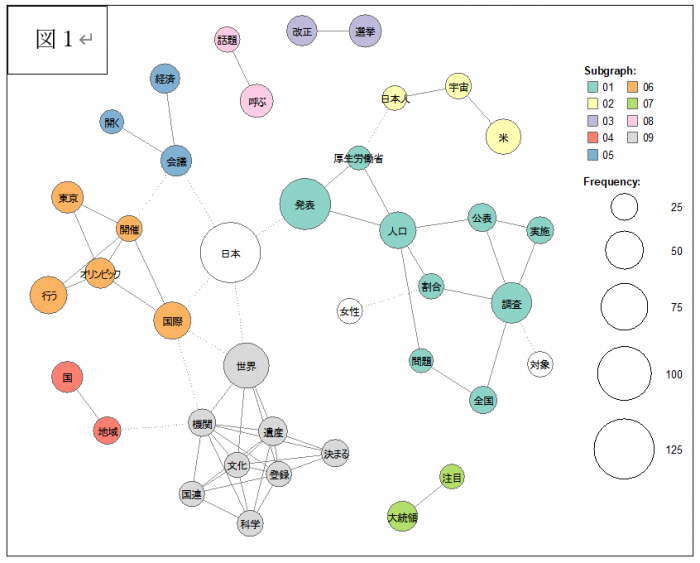
これより、
・政府が公表した調査結果を基にした出題、特に厚生労働省の人口統計(子ども数、高齢者数、女性に関する数など)[青緑色のブロック]
・オリンピックや東京オリンピック(選手やメダル数)[燈色のブロック]
・世界遺産に関連した話題(あらたに登録された地域など)[灰色]
・選挙に関する話題(大統領選もとりあげている)[黄緑色のブロック]
・経済に関する話題[深緑色のブロック]
・日本やアメリカにおける宇宙に関する話題[黄色のブロック]
などがよく出てきたこと、すなわち、600強の出題の中で、よく出ていた分野・話題であることがわかります。
図2は単語と出題者で対応分析を行い、その結果を2次元散布図に表したものです。対応分析は、出現パターンが似通った単語は、原点から同じ方向で、近くに配置されます。どの文書にも登場する単語は原点近くに、特定の文書に偏って出現する単語は原点から離れた場所に配置されます。また、出題者も含めて分析すると、出題者にも同じような配置が与えられるので、単語との関連が見えるようになります。
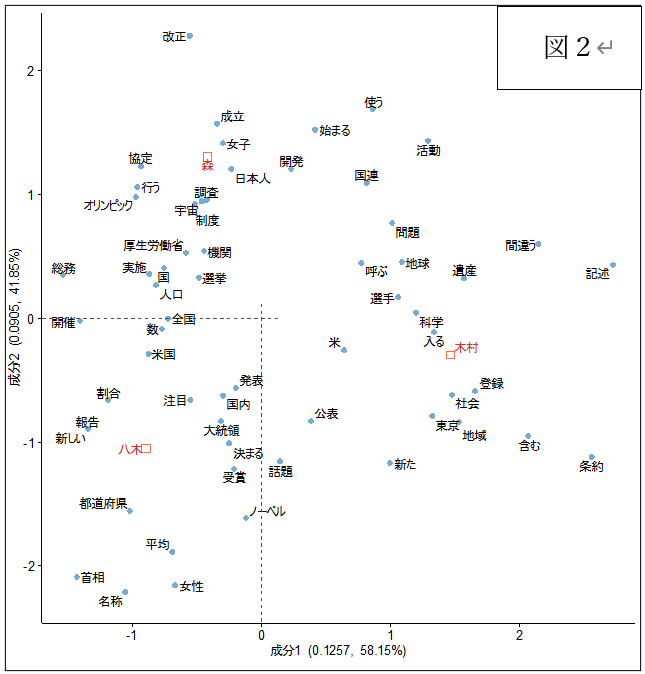
これより、3人の出題者(森、八木、木村)との関係のみ、みてみると、
・森は、「日本人」、「女子」、「調査」、「制度」、「厚生労働省」、「開発」、「宇宙」、「オリンピック」などが特徴的なので、統計的なネタ、日本や女子に関する話題、制度に関連する話題を多く取り上げていたことがわかります。また、宇宙(開発)やスポーツネタも多かったようで、「改正」が同じ方向にあることから、法令等が改正されると、出題に使っていたことがみてとれます。
・八木は、「報告」、「割合」、「都道府県」、「大統領」、「首相」、「受賞」、「ノーベル」が特徴的です。「平均」や「女性」という単語もみられることから、八木も統計的な話題が多かったといえます。また、政治的な話題も多いことがわかります。ノーベル賞はよく取り上げていたようです。
・木村は、「科学」、「選手」、「地球」、「遺産」、「登録」、「東京」、「地域」、「社会」と、科学ネタ、世界遺産関係、地域の問題(特に、東京)などを多く取り上げていたようです。「条約」が特徴的ですので、社会ネタも多かったようです。
ということで、全体的な出題傾向や出題者による違いなどもみることができました。このように、テキストマイニングでは、テキスト型のデータの分析ができるということです。
