miniレクチャー
データサイエンス
よく似たグループを見つけるには? ~クラスター分析で分類~
集団をいくつかのグループに分ける
集団をいくつかのグループに分けたい、ある対象とよく似た対象はどれかを知りたい、といった場面が多々あります。このグループ分けをすることをクラスタリングやセグメンテーションといいます。
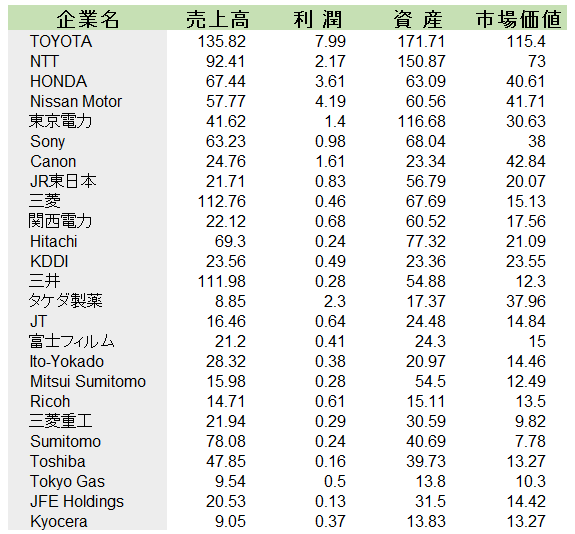
たとえば、下の表のような、日本企業25社の売上高、利潤、資産、市場価値を調べたデータを使って、この25社をいくつかのグループに分けてみましょう。クラスター分析という手法を使います。
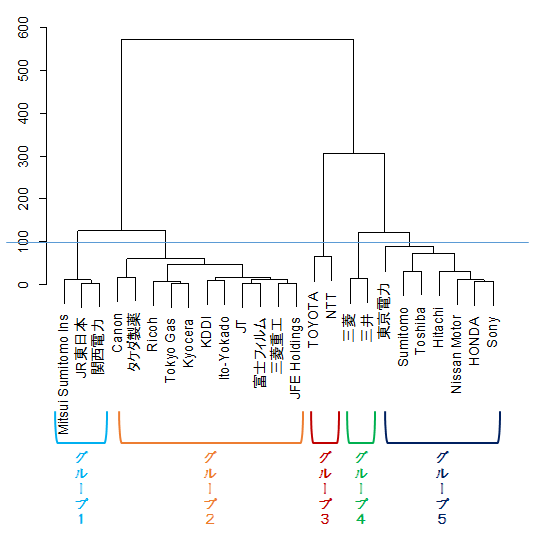
表の下にあるトーナメント表のように見える図がその結果です。デンドログラムといいます。「房にぶら下がっている葡萄」を想像すると理解がしやすいと思います。
図のように、高さ100のところで切り取ってみると、5つの房(5つのグループ)に分けることができますね。高さ200だと、3グループになります。
TOYOTAとNTTの属するグループ3は、市場価値・資産・売上高ともにかなり高い企業、グループ4は、市場価値・資産・利潤は低いが、売上高が高い企業といったことがわかります。
クラスター分析
クラスター分析は、企業の売上高や市場価値のような量的なデータを用いて、似ている者同士を同じグループにまとめる手法です。
クラスター分析の特徴は、売上高や市場価値などの一つの変数のみでグループに分けるのではなく、いくつかの変数(この例の場合は4つの変数)を組み合わせて、お互いの企業間の近さ(類似度)または遠さ(非類似度)を測って、グルーピングできることです。つまり、総合的な観点から企業の分類ができるのです。この類似度(非類似度)をグラフの縦軸にとって、トーナメント表のように結んだのがデンドログラムです。
クラスター分析は、購買層の分類やブランドの分類など、マーケティングリサーチの分野にも多く利用されているデータサイエンスの基本的な手法です。
