miniレクチャー
なぜこんなにも早く当確が出るの? ~選挙の出口予想の仕組み~
どんなふうに予想してるの??
「Σ候補に当確が出ました!」選挙は、国民の一大イベントであり、日本の将来を考えるうえでも最も大事なイベントであることは間違いないと思います。最近では選挙時において、必ずテレビ等で特番が放送されていますが、その中でテレビ番組によって当確に違いが見られることや、候補者によって当確が出る時間の違いに疑問を持ったことはありませんか?
実はその仕組みにおいては、データ・サイエンスが大活躍しています。
選挙の当確を出すためには、それぞれの候補者の得票率を
「だいたいこのくらいからこのくらいまでの区間に入ってるんじゃないかな?」
と、区間で推定する必要があります。その方法の詳細はここでは省略しますが、仮に、出口調査で得られたある候補者の得票率をpとすると、その区間は、pの前後
![]()
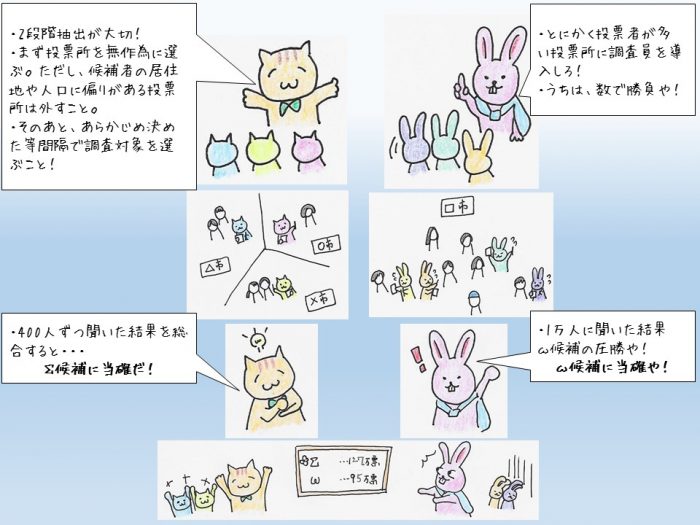
の間であることが知られています。ここで、nは出口調査で必要な人数(標本の大きさといいます)であり、誤差を少なく区間を推定するためには、無作為に選ばれた400人程度が必要と考えられています。
たとえば、ある市長選挙において、候補者はΣ氏とω氏の2人とし、400人に聞いた出口調査の結果が、Σ候補が224人、ω候補が176人であったとしましょう。このとき、Σ候補の出口調査での得票率は、
![]()
ですので、市全体の得票率の区間は、
![]() と
と ![]()
の間、すなわち、0.51と0.61の区間に含まれていることになります。候補者が2人の場合の「当確」は、区間の下限が50%を超えていればよいわけですから、この場合「Σ候補に当確が出ました!」とすることができます。
ということで、テレビ局などがそれぞれ独自に行った出口調査の集計が終わりさえすれば、開票のさなかに「当確」を発表できるわけです(実際には、開票の進行具合や、事前の世論調査、候補者の知名度、組織票の強さ、担当記者の分析など、いろいろな要素を加味して予測を発表しています)。
どんな人たちを調査すればいいの??
こういった予測を行うための調査では、調査する集団の偏りに注意する必要があります。
出口調査では、主に2段階抽出とよばれる方法が取られています。はじめに特別な得票所(候補者の自宅がある、人口に偏りがあるなど)を除外した状態で無作為に投票所を選び、その後、選ばれた得票所において、調査員があらかじめ決められた人数間隔で、投票者に協力を依頼し、誰に投票したかなどを教えてもらいます。
予測調査においては、他にも郵送調査や電話調査による方法が取られていますが、調査する対象をどのような集団にするかが非常に重要です。
有名な失敗例として、アメリカの調査会社であるダイジェスト社がよくあげられます。1936年のアメリカ大統領選挙の予測において、当時絶大の信頼を得ていたダイジェスト社は、約1000万枚のはがきを発送し、約200万以上の回答を得、それらを単純に集計し、共和党候補のランドン氏の当選を予測しました。一方、前年に参入したばかりの別の調査会社であるギャラップ社は、調査対象の偏りをできる限り少なくするための抽出方法を用いて、約5万人から約3000の回答を得て、民主党候補のルーズベルト氏の当選を予測しました。結果は、ルーズベルト氏が当選し、選挙予測はギャラップ社の勝利に終わりました。
ダイジェスト社の失敗の原因は、調査の対象を自社雑誌の定期購読者や電話帳、自動車登録名簿に載っている人にしたからだと考えられています。当時のアメリカは、まさに大恐慌であり、比較的豊かな人々は共和党を、それほど豊かでない人々は民主党を支持する傾向に分かれていました。雑誌の購読を続けられる人々や電話、自動車などの保持者には富裕層が多いため、ダイジェストの予測は、その標本の偏りを反映した結果となったわけです。一方、ギャラップ社は、マーケティング調査の経験があり、標本の偏りを少なくする科学的な抽出方法を用いました。その方法は、収入状態、居住地域、性別などで偏りがないように標本を決めるものでした(「割り当て法」といいます)。その結果、標本は母集団に近い姿となり、ギャラップ社はダイジェスト社よりはるかに小さい標本から正しい予測を行うことができたのです。(実は、この後、ギャラップ社も失敗をします。そのことにより、さらに調査のデータ・サイエンスは発展します。調査の歴史をひも解いてみるのもおもしろいですよ・・・!)
「販売した製品が消費者にどのように評価されているのか知りたい」、「いまの若者の志向をとらえた新商品を売り出したい」なんていうとき、その調査のためには、正しく対象者を選ばないといけないのですね。